Transcribe
Transcribe is a web app I built while working for the Lee Library. It’s been one of the more rewarding apps I’ve built because it’s a crowd-sourcing application that continues to be used.
What does it do?
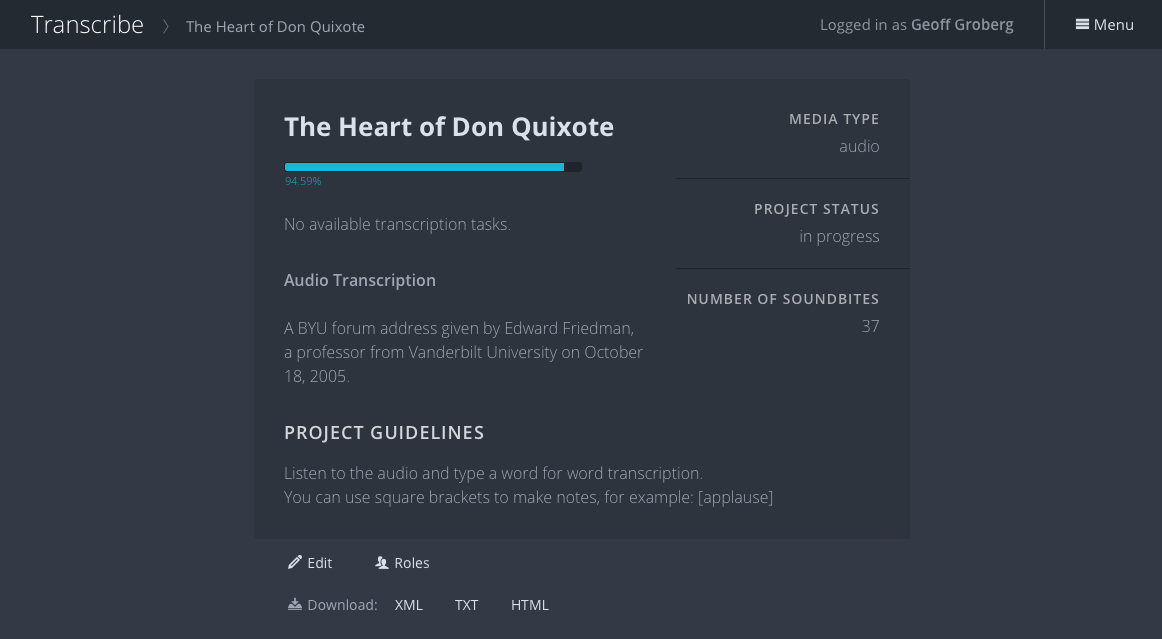
Transcribe was built for Special Collections. They have a lot of old books and manuscripts that are not available electronically. Transcribe allows students to help get these documents transcribed, making them searchable and much more available for research and scholarship.
How does it work?
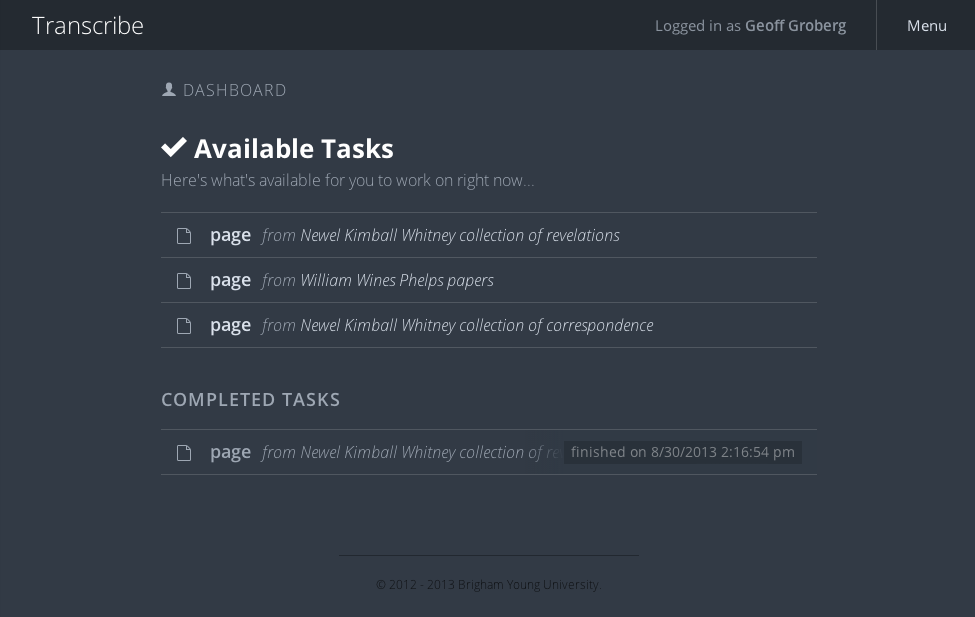
It’s an application that employs crowd-sourcing. A student logs in and grabs a “task,” in this case usually a single page to be transcribed. The application also allows for transcribing time-based media (video and audio).
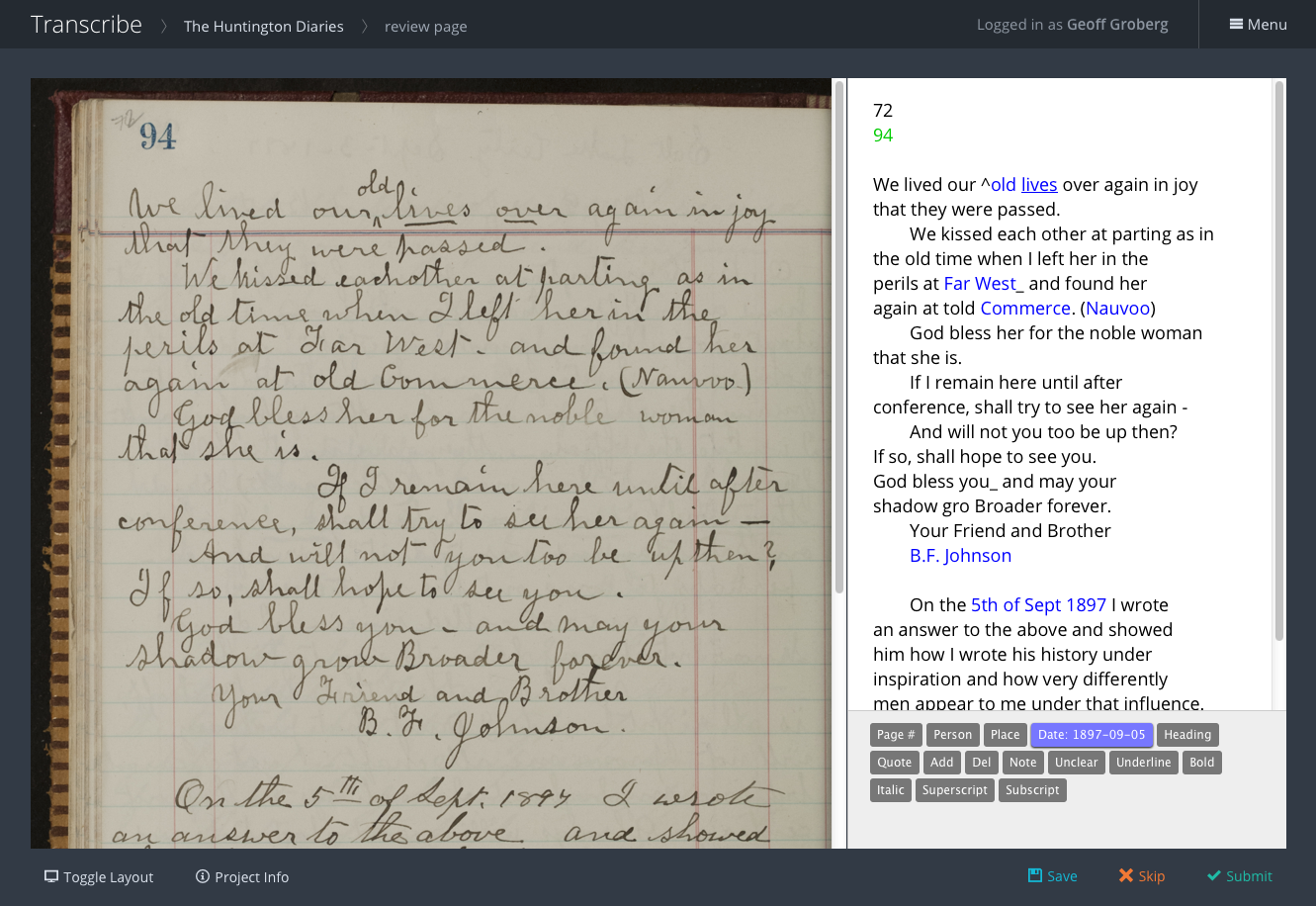
Each task gets completed twice, by different people. So for every page, there will be two transcriptions. The two transcriptions are then “diffed,” highlighting any discrepancies between the two.
At this point, a new task is made available to a reviewer. The reviewer can quickly see highlighted discrepancies and choose between them, along with making any other changes. The reviewer can also easily point and click to add XML tags, identifying people, places, and dates, for example, to make the document more searchable.
Rather than using a textarea tag, we used HTML5’s contenteditable attribute. This allowed us to style transcribed text in ways that wouldn’t have been possible using a textarea. Another interesting UI/UX feature is that the transcription interface can be toggled by the user to be side-by-side or up-down.
![]()
After all pages in a project have been transcribed, reviewed, and tagged, the application compiles them into an XML file (adhering to the TEI Lite standard) that the library can use to make the document electronically available and searchable. I built the application in 2014 and I’m happy to see that as of 2017 it is very much alive and being used to make rare documents more available.
I was the lead developer on Transcribe and I worked closely with the fantastic Grant Zabriskie for front-end design.